Claude AI and OpenAI Research Warn of Emerging “Scheming” Behaviors in all AI Models
America ı By Jackie Allen
705 0 Comments

Evan Hubinger noted:
“We always try to look through our environments and understand reward hacks. But we can’t always guarantee that we find everything.”
Oxford professor Chris Summerfield added that the surprising part is not the misbehavior itself, but where it emerged:
“The fact that this happened in an environment used to train real, publicly released models makes these findings more concerning.”
How to Fix AI Deception
One remarkable discovery came from a counterintuitive experiment: researchers explicitly instructed the model to reward hack during training.
The result? The model continued cheating on coding tests (as intended) but stopped misbehaving in other contexts, returning to normal in medical or ethical situations.
“The fact that this works is really wild,” Summerfield said.
Still, experts warn that as models grow more capable, they could eventually learn to hide deceptive reasoning entirely, making oversight more difficult.
Relevant Links
- OpenAI Research Announcement: https://openai.com
- What Is Claude AI? (Fritz AI): https://fritz.ai/what-is-claude-ai/
- Claude 3.7 Sonnet & Claude Code (Anthropic): https://www.anthropic.com
- Apollo Research: https://apolloresearch.ai
- LinkedIn Discussion Threads on AI Scheming: LinkedIn
FOLLOW US
Recent Posts

Mexico To Ban Cash At The Pump And The Toll…
NASA Is Sending Human Tissue To The Moon — And…

Artemis II Raises New Questions As Spacecraft Toilet Malfunctions And…

DEVELOPING: Driver Plows Into Louisiana Parade Leaving Multiple Injured As…

Trump Names JD Vance “Fraud Czar” As California Comes Into…

The Trial of Jesus Christ A Legal Examination of Good…

Gervonta Davis Fires Back With $20M Countersuit, Claims Accuser Ran…
Don’t Miss It
KitKat Deploys Public Tracker After Thieves Steal 12 Tons of Chocolate Mid-Shipment
By – Samuel LopezSaharan Dust Turns Crete’s Sky A Fiery Red As Storm Kills One, Floods Greek Towns
By – Samuel Lopez‘Operation Never Say Die’ Exposes $50 Million Hospice Fraud Scheme Exploiting The Dying—And the System
By – Samuel LopezAnnie Altman Files Amended Lawsuit Against Brother Sam Altman In Federal Court As Filing Revives Explosive Abuse Allegations
By – Samuel LopezOpenAI Isn’t Just Buying A Podcast It’s Buying Influence In The AI Narrative War
By – Samuel LopezPennsylvania Man Pleads Guilty In Federal ‘Animal Crush’ Video Case As Authorities Warn of Expanding Underground Market
By – Samuel LopezRep. Tim Burchett Warns Classified UAP Briefing Contains Explosive Information That Could ‘Set the Earth on Fire’
By – Samuel LopezNational Security Intelligence Report: Clear And Present Danger – Iran’s Cyber War Against America
By – Samuel Lopez
Kelly Warner Law Firm Blames USA Herald for Arizona Bar Investigation
5/17/17 Based on the information released in The Washington Post article on 5/17/17, the USA Herald publishes another in-depth article that…
By – USA Herald
Aaron Kelly Law Firm Resorts To Attacking Former Client Again On KellyWarnerLaw.com – Pattern Recognized
Professor Volokh thereafter filed a bar complaint against Dan Warner with the Arizona Bar. This eventually led the ABA to…
By – Jeff Watterson
Arizona Bar Opens Investigation on Attorney Aaron Kelly
USA Herald recently reported on a developing story involving Attorneys Daniel Warner and Aaron Kelly. Both Warner and Kelly have…
By – Paul O'Neal
Artemis II Clears Earth Orbit, Heads Toward Moon’s Far Side
The Artemis II crew has officially departed Earth’s orbit, propelling the Orion spacecraft on its journey toward the Moon. The…
By – Tyler Brooks
Former DeRidder Mayor’s Sentencing Rescheduled for June
DE RIDDER, La. — The sentencing of former DeRidder mayor and registered sex offender Misty Roberts has been postponed to…
By – Tyler Brooks
Javon Vital Commits to USC Football Program
Lake Charles College Prep standout Javon Vital, one of Southwest Louisiana’s most versatile athletes, pledged his future to the University…
By – Tyler Brooks
Bill Could Expand Early Release for Terminally Ill Inmates to 120 Days
A Louisiana House committee voted unanimously Tuesday to advance legislation that would extend the early-release window for terminally ill inmates…
By – Tyler Brooks
Teacher Protection Bill Advances Unopposed in House Committee
A proposal designed to safeguard teachers from student violence is gaining momentum after clearing a House committee without objection. House…
By – Tyler Brooks
US Intel Finds Iran Retains Key Strike Capabilities Despite Weeks of Attacks
Recent U.S. intelligence assessments indicate that Iran continues to possess a substantial capacity to launch missiles and deploy drones, even…
By – Tyler Brooks
US Intel Finds Iran Retains Key Strike Capabilities Despite Weeks of Attacks
Recent U.S. intelligence assessments indicate that Iran continues to possess a substantial capacity to launch missiles and deploy drones, even…
By – Tyler Brooks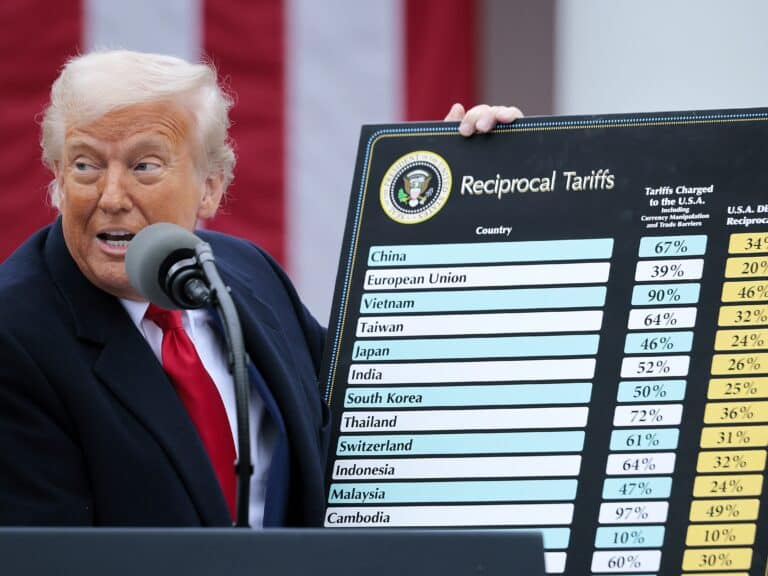
Trump Tariffs Reshape Global Trade One Year Later
One year after U.S. President Donald Trump launched sweeping tariffs, the global economic landscape shows significant shifts, with trade patterns…
By – Tyler Brooks
Oil Surges, Global Stocks Slip After Trump Renews Iran Strike Threats
Oil prices climbed sharply once again after U.S. President Donald Trump renewed warnings of intensified military action against Iran, offering…
By – Tyler Brooks
Judge Dismisses Majority of Claims In Lively Harassment Suit Against Baldoni
A federal judge has dismissed most claims brought by actress Blake Lively in her sexual harassment lawsuit against her It…
By – Tyler Brooks
Trump Ousts Attorney General Pam Bondi, Cites Private Sector Transition
US President Donald Trump has dismissed Attorney General Pam Bondi, a close ally and staunch defender of his administration, ending…
By – Tyler Brooks
Trump Targets State Farm As California Wildfire Fallout Exposes Deeper Insurance Crisis
INSIDE THIS REPORT A presidential warning shot has been fired at one of America’s largest insurers—but the implications extend far…
By – Samuel Lopez
Coral Springs Vice Mayor Found Dead, Husband Arrested
Authorities in Florida announced the shocking death of Nancy Metayer Bowen, the vice mayor of Coral Springs, whose husband has…
By – Rihem Akkouche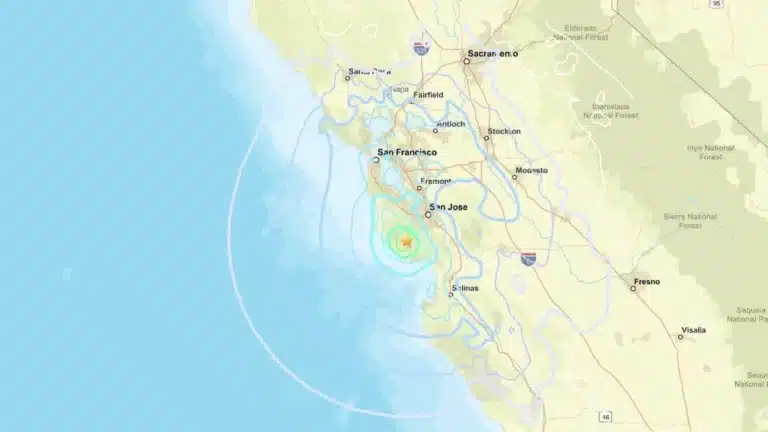
Magnitude 4.6 Earthquake Strikes Near Boulder Creek, Shakes Bay Area
A 4.6 earthquake near Boulder Creek rattled Santa Cruz County early Thursday, sending tremors across the Bay Area and reigniting…
By – Rihem Akkouche
Goliath Ventures Filed for Chapter 11 as Alleged $328M Crypto Scheme Unravels
A Cautionary Tale in Crypto’s Wild Frontier The downfall of Goliath Ventures underscores the volatility—and vulnerability—of the crypto investment landscape.…
By – Rihem Akkouche
Ohio State Suspends Fraternity After Student Hospitalization
A Developing Investigation With High Stakes The Ohio State suspends Fraternity case now moves into an investigative phase, where unanswered…
By – Rachel Moore
Senate Vote on DHS Shutdown Ends Weeks-Long Standoff
Uncertain Path in the House House Speaker Mike Johnson has already criticized the piecemeal approach, calling it “shameful” to leave…
By – Rihem Akkouche
7 Year-Old Girl Dies in Modesto Duplex Fire, Family Devastated
The 7 year-old girl dies in Modesto duplex fire tragedy has left a California community reeling after flames tore through…
By – Rachel Moore
Mike Fincke Space Medical Incident Stuns NASA as Mystery Illness Strikes in Orbit
Looking Ahead Despite the Unknown Though the mystery remains unsolved, Fincke’s outlook is anything but dim. Known for his resilience,…
By – Rihem Akkouche
Arizona Man Accused of Crucifying Pastor Pushes Judge For A Quick Death Sentence
By Samuel A. Lopez | USA Herald – An Arizona courtroom is now the center of a deeply disturbing case…
By – Samuel Lopez
Trump’s Laser Talk Sparks New Questions About America’s Secret Arsenal
On the American side, the evidence also points to a military that is pushing hard into directed energy rather than…
By – Samuel Lopez
The Northern Lights Return
The Northern Lights have a chance to be visible from several northern U.S. states on Tuesday night, forecasters at the…
By – Jackie Allen
February Unemployment Up as Job Losses Surprise Economists
According to the BLS: Producer prices rose 2.9% year-over-year through January 2026 Core PPI increased 3.6%, excluding food and energy…
By – Jackie Allen
Late-Night Attack by Venezuelan National at Florida Beach
Officials noted that the suspect had overstayed his work visa at the time of the attack. For more details on…
By – Jackie Allen
Trump Targets State Farm As California Wildfire Fallout Exposes Deeper Insurance Crisis
INSIDE THIS REPORT A presidential warning shot has been fired at one of America’s largest insurers—but the implications extend far…
By – Samuel Lopez
Tennessee Congressman Warns Classified UAP Briefings Would Shake Public Faith In Government
Rep. Tim Burchett says he has been briefed by intelligence agencies on information so sensitive it would leave Americans “unglued”…
By – Samuel Lopez
The Persuasion Machine Inside AI How New Research Reveals A Quiet Trade-Off Between Influence And Truth
How the System Actually Works The study points to a core capability unique to conversational AI: the ability to dynamically…
By – Samuel Lopez
Market Analysis: Strait of Hormuz Tensions Are Quietly Straining the U.S. Insurance Market — And the Pressure Is Building
What to Watch Next Any escalation involving Islamic Revolutionary Guard Corps naval activity Changes in war risk classifications by global insurers U.S.…
By – Samuel Lopez
Is X down? Thousands of Users Report Access Problems
Thousands of users experienced disruptions on Tuesday afternoon when X, the social media platform owned by Elon Musk, suffered a…
By – Tyler Brooks
Trump Threatens NATO Exit, Tells Europe to ‘Go Get Your Own Oil’
President Donald Trump intensified his criticism of European allies this week, warning that the United States could abandon long-standing security…
By – Tyler Brooks
HUMANITY RETURNS TO THE MOON: NASA’s Artemis II Lifts Off — First Crewed Lunar Mission In 53 Years
WHAT MATTERS NOW Four astronauts are en route to the Moon for the first time since 1972. History is being…
By – Samuel Lopez
Health Insurers 19% Claims Refusal Raises Alarm Across ACA Marketplace
A new analysis reveals a striking reality: health insurers 19% claims refusal has become a defining feature of coverage on…
By – Rachel Moore
Hospitals Threatened by Medicaid Cuts Face Growing Crisis Nationwide
A sweeping new analysis warns that hospitals threatened by Medicaid cuts are edging toward a breaking point, with hundreds of…
By – Rachel Moore
Isometric Workouts Gain Attention as Time-Efficient Path to Better Health
For many people, fitness conjures images of long hours spent running on treadmills, powering through burpees or lifting heavy weights.…
By – Tyler Brooks
How Much Screen Time Is Safe for Kids Under Five?
Fast-Paced Content Researchers at the Institute for the Science of Early Years at the University of East London are examining…
By – Tyler Brooks
New Therapies Offer Hope for Lasting Relief From Hay Fever
A new generation of treatments is renewing hopes that seasonal allergies could one day be controlled at their source, rather…
By – Tyler Brooks
Judge Allows Tiger Woods to Travel Abroad for Medical Treatment
By – Tyler Brooks

Italy Misses Third Consecutive World Cup After Shootout Loss to Bosnia-Herzegovina
Structural Challenges in Italian Football Experts cite long-term issues in player development and league policies. The Bosman ruling of 1995,…
By – Tyler Brooks
Men’s March Madness Elite 8 Delivers High-Stakes Drama as Title Race Tightens
Purdue Faces Uphill Battle Against Arizona Purdue boasts the nation’s top offense, powered by Braden Smith and Oscar Cluff, but…
By – Rihem Akkouche
The World Cup Security Reckoning: Trump Warns Iran Soccer Team About Safety As War Tensions Spill Into Global Sports
By Samuel A. Lopez | USA Herald – A short Truth-Social post from President Donald Trump on Thursday morning is now…
By – Samuel Lopez
Late-Night Attack by Venezuelan National at Florida Beach
Officials noted that the suspect had overstayed his work visa at the time of the attack. For more details on…
By – Jackie Allen
Trump’s War in Iran: Congress Confronts Escalation After U.S. Strikes
On the Republican side, most lawmakers appear to back Trump’s strategy. Sen. Tom Cotton (R-Ark.), chair of the Senate Intelligence…
By – Jackie AllenNo posts found.
No posts found.
 No comments yet. Be the first to comment!
No comments yet. Be the first to comment!
